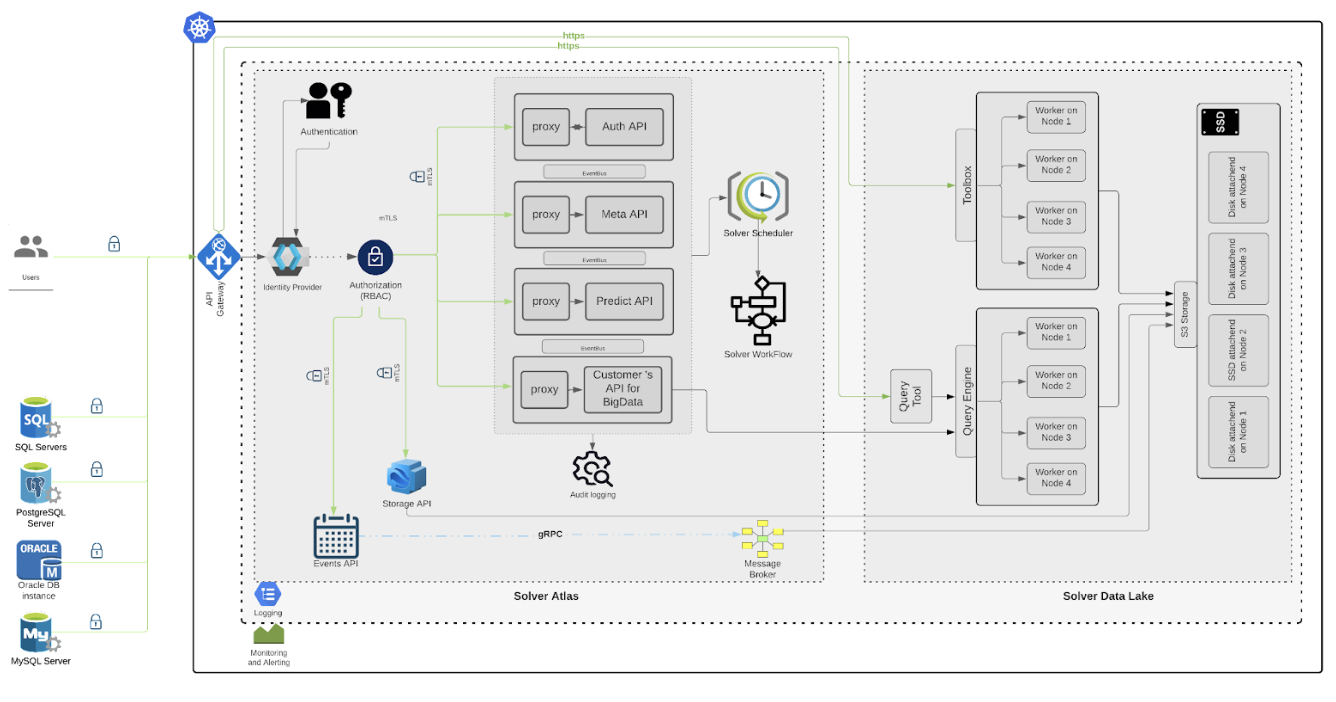
Solver Data Lake
A Data Lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics-from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions. A data lake is different because it stores relational data from a line of business applications, and non-relational data from mobile apps, IoT devices, and social media. The structure of the data or schema is not defined when data is captured. This means you can store all of your data without careful design or the need to know what questions you might need answers for in the future. Different types of analytics on your data like SQL queries, big data analytics, full-text search, real-time analytics, and machine learning can be used to uncover insights.\ As organizations with data warehouses see the benefits of data lakes, they are evolving their warehouse to include data lakes, and enable diverse query capabilities, data science use-cases, and advanced capabilities for discovering new information models. Gartner names this evolution the "Data Management Solution for Analytics" or "DMSA" - Object Storage S3 compliant.
- Solver Data Lake is providing a way to create Block, Object, and File storage classes in Kubernetes clusterized environment. Furthermore, Kubernetes pods can now claim parts of Block storage in HA (High Availability) mode (RWO access). When Object storage is created it gives us a way to communicate over S3 API in Cloud Native way. File storage gives us RWX access to underlying data. This component enables the end-users to persist the desired data at scale for further use, and organize it in a structured manner with implementing the desired logic in application components that can communicate with it. Object Storage S3 compliant provides full data democratization and accessibility through many programming languages. Also, supports multi-tenancy used to distinguish different levels and permissions of users.
Query Engine
- Solver Data Lake has integrated Trino as a distributed SQL query engine for big data. Designed from the ground up for fast analytic queries against data of any size. It supports both non-relational sources, such as the Hadoop Distributed File System, Amazon S3, Cassandra, MongoDB, and relational data sources such as MySQL, PostgreSQL, Amazon Redshift, Microsoft SQL Server, and Teradata. Main capabilities include the possibility to query data where it is stored, no need to load data into a specific structured database engine. It can be performed on CSV or parquet files (gzip including). Also, it supports subdirectory structure recognition.
Spark Operator
- Spark Operator is used for operating Spark jobs applications in HA (High Availability) mode. It is designed to run jobs on-demand or on schedule. For end-users, it enables the applicative utilization of the data persisted in object storage objects, at scale. With this operator, Spark has direct access to data lake (object storage)
Data Monitoring
- Data Monitoring is a service that provides monitoring of raw data arrivals on object storage and trigger alerting service in case of anomalies. Configuration is changeable and can be expanded as the amount of raw data and number of sources is growing. This way, in case of missing data or some problems with export, alerts will be raised. Service will monitor if data has arrived and the minimum size is satisfied.